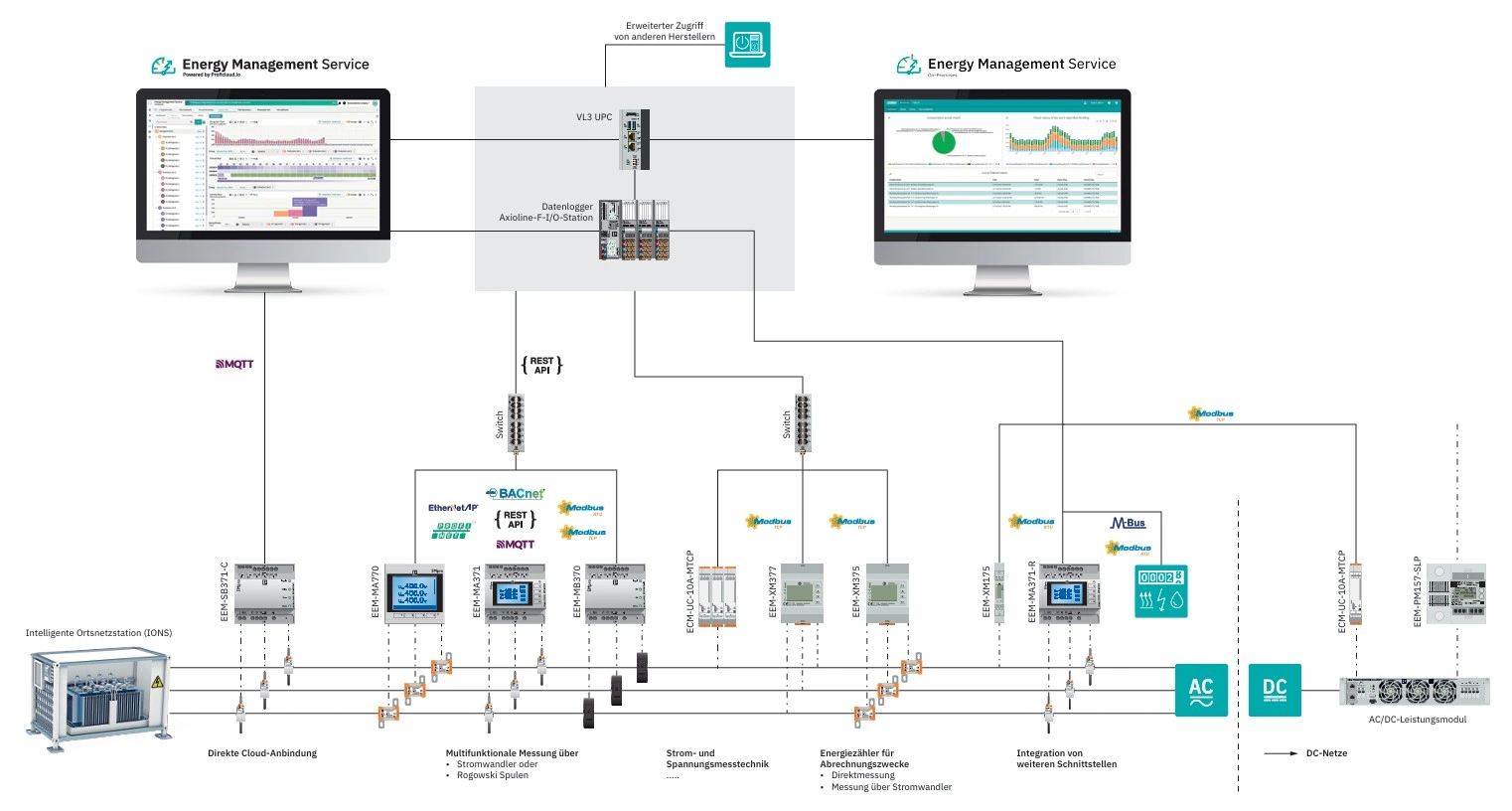



The trend towards digitization involves both opportunities and risks for the industry because digitization requires large computing power and storage capacities. Industrial cloud computing enables companies to process and evaluate the growing volumes of data in order to optimize the entire value chain.
When talking about cloud computing, it is assumed that there is a connection to the cloud via the internet. However, in many applications data must be collected, checked and fed back into the process in very short cycles. In such a scenario, a public cloud solution would not be suitable because of the latency periods found on the internet. Edge or fog computing solutions are therefore increasingly being used in such applications. But how do these models differ? What are the advantages and disadvantages?
Edge: Direct evaluation at the point of origin
Edge computing gives the user the possibility to evaluate the recorded data with network technologies directly at its point of origin: “at the edge”. With edge computing, powerful analysis technologies are thus available practically everywhere and at any time. In this way, employees who need to monitor the condition of machinery and equipment installed in remote areas can determine the need for maintenance or spare parts much more accurately. Edge computing is therefore proving to be an alternative for companies that do not have immediate access to high bandwidth and a fast route to the cloud. This applies, for example, to the operators of water extraction plants as well as solar and wind energy plants. On the basis of the condition-based maintenance concepts described above, in which machines and equipment are monitored in real time, service costs can be significantly reduced and productivity increased accordingly.
Central processing of data from multiple devices

The terms edge and fog computing are often used synonymously and are also very similar. Both approaches focus on the idea of shifting computing power from the cloud to the data source. Edge and fog only differ in the degree of this shift. In fog computing, data from several end devices is collected and processed at a central location – very similar to the actual cloud idea. However, the place where data is processed is not located in a large data center of the cloud provider. Instead, a kind of “mini computer centre” is used, which is usually located at the same site as, for example, the control systems that supply the data. There, for example, time-sensitive calculations are made which have an influence on the machine and can only be done locally. A global analysis and further processing of the data continues to take place in the higher-level cloud system.
Edge computing goes even further at this point: here, data (pre-)processing actually takes place in the individual devices in which the data is created. Such a concept therefore places higher demands on the locally installed devices in terms of computing power, openness and access security.
In order to understand the advantages of edge and fog computing, the first question that arises is why a pure cloud system is not used. Cloud systems have already proven their advantages such as reliability, cost savings or worldwide availability. Even when the cloud has almost unlimited storage and computing capacity, the challenge remains: Just because the large data centers have very good network connections, this does not automatically apply to the devices installed in the field.

In order for companies to really participate in digitization, the components mounted in remote locations must also be able to be connected to the Internet of Things (IoT). An example is the control system installed in a solar park. Although it collects valuable data for the operator, it is only connected to the network via a slow GSM connection. Here, it quickly becomes clear why the data cannot be immediately transferred to a cloud system: The bandwidth is simply not sufficient. In this example edge computing ensures that the solar farm operator can still work sensibly with the controller data by moving some of the work to be performed from the cloud to the device.
While edge computing processes data individually in the devices where the data is generated, fog computing collects data from multiple devices in a central spot to be processed in a data center in the same location. This is the key difference in the degree of relocation of the two devices.
Data usage despite bad internet connection
Overall, it can be said that edge and fog computing will not displace or replace the cloud. They only serve to soften the previous restrictions on using the cloud. Edge devices are able to perform simple real-time analyses and pre-collect sensor data according to specific criteria before transferring it further into the cloud. This prevents unnecessary load on the cloud connection. The (relative) independence from an internet connection and the particularly low latency can also be arguments for the use of edge devices in IoT projects.
